本文共 8436 字,大约阅读时间需要 28 分钟。
ES中有几个基本概念:索引(index)、类型(type)、文档(document)、映射(mapping)等。
ES数据架构的主要概念(与关系数据库Mysql对比)
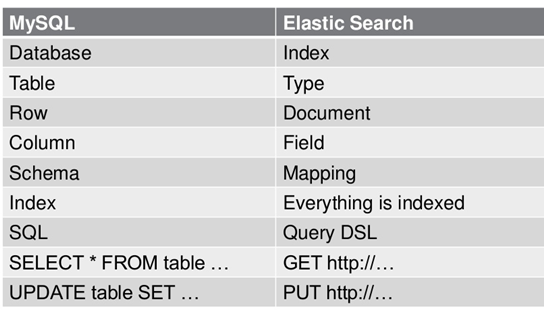
索引(index):
索引是ES的一个逻辑存储,对应关系型数据库中的库,ES可以把索引数据存放到服务器中,也可以sharding(分片)后存储到多台服务器上。每个索引有一个或多个分片,每个分片可以有多个副本。类型(type):
ES中,一个索引可以存储多个用于不同用途的对象,可以通过类型来区分索引中的不同对象,对应关系型数据库中表的概念。但是在ES6.0开始,类型的概念被废弃,ES7中将它完全删除。删除type的原因:
我们一直认为ES中的“index”类似于关系型数据库的“database”,而“type”相当于一个数据表。ES的开发者们认为这是一个糟糕的认识。例如:关系型数据库中两个数据表示是独立的,即使他们里面有相同名称的列也不影响使用,但ES中不是这样的。
我们都知道elasticsearch是基于Lucene开发的搜索引擎,而ES中不同type下名称相同的filed最终在Lucene中的处理方式是一样的。举个例子,两个不同type下的两个user_name,在ES同一个索引下其实被认为是同一个filed,你必须在两个不同的type中定义不同的filed映射。否则,不同type中的相同字段名称就会在处理中出现冲突的情况,导致Lucene处理效率下降。
去掉type能够使数据存储在独立的index中,这样即使有相同的字段名称也不会出现冲突,就像ElasticSearch出现的第一句话一样“你知道的,为了搜索····”,去掉type就是为了提高ES处理数据的效率。
除此之外,在同一个索引的不同type下存储字段数不一样的实体会导致存储中出现稀疏数据,影响Lucene压缩文档的能力,导致ES查询效率的降低
文档(document):
存储在ES中的主要实体叫文档,可以理解为关系型数据库中表的一行数据记录。每个文档由多个字段(field)组成。区别于关系型数据库的是,ES是一个非结构化的数据库,每个文档可以有不同的字段,并且有一个唯一标识。映射(mapping):
mapping是对索引库中的索引字段及其数据类型进行定义,类似于关系型数据库中的表结构。ES默认动态创建索引和索引类型的mapping,这就像是关系型数据中的,无需定义表机构,更不用指定字段的数据类型。当然也可以手动指定mapping类型。ES集群核心概念:
接近实时(NRT)
Elasticsearch是一个接近实时的搜索平台。这意味着,从索引一个文档直到这个文档能够被搜索到有一个轻微的延迟(通常是1秒)。1、集群(cluster)
集群架构图:
分布式架构原理:
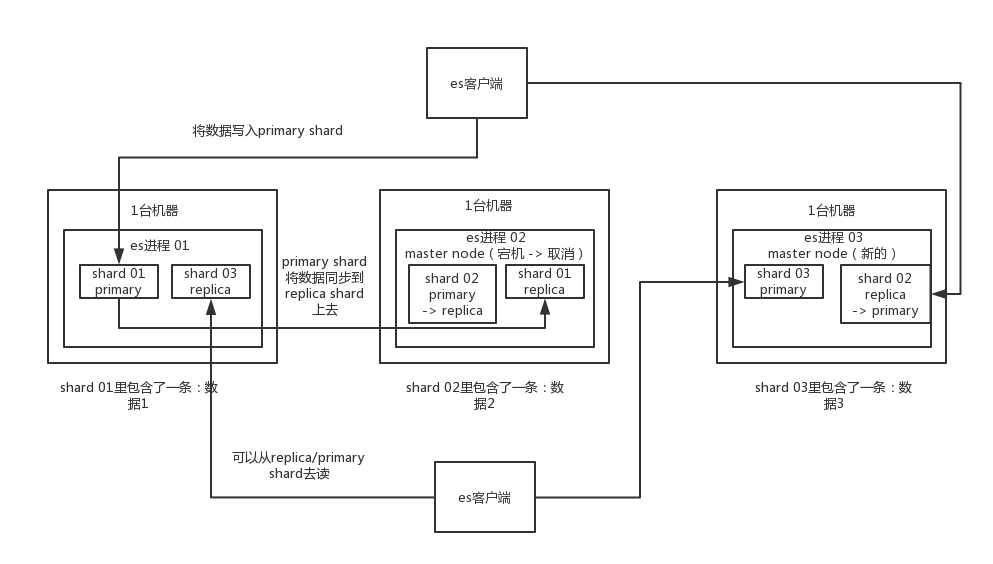
es中存储数据的基本单位是索引
index:mysql里的一张表 ,一个index里可以有多个type 每个type有一个mapping,mapping就是这个type的表结构 接着你搞一个索引,这个索引可以拆分成多个shard,每个shard存储部分数据。 这个shard的数据实际是有多个备份,每个shard都有一个primary shard,负责写入数据 但是还有几个replica shard。primary shard写入数据之后,会将数据同步到其他几个replica shard上去。(高可用)ES可以作为一个独立的单个搜索服务器。不过,为了处理大型数据集,实现容错和高可用性,ES可以运行在许多互相合作的服务器上。这些服务器的集合称为集群。 一个ES集群由多个节点(node)组成, 每个集群都有一个共同的集群名称做为标识
这个名字默认就是“elasticsearch”。这个名字是重要的,因为一个节点只能通过指定某个集群的名字,来加入这个集群。在产品环境中显式地设定这个名字是一个好习惯,但是使用默认值来进行测试/开发也是不错的。
2、节点(node)
一个es实例即为一个节点,一台机器可以有多个节点,正常使用下每个实例都应该会部署在不同的机器上。ES的配置文件中可以通过node.master、 node.data 来设置节点类型node.master: true/false 表示节点是否具有成为主节点的资格
node.data: true/false 表示节点是否为存储数据 node节点的组合方式:主节点+数据节点: 默认方式,节点既可以作为主节点,又存储数据
数据节点: 节点只存储数据,不参与主节点选举 客户端节点: 不会成为主节点,也不存储数据,主要针对海量请求时进行负载均衡3、分片(shard):
如果我们的索引数据量很大,超过硬件存放单个文件的限制,就会影响查询请求的速度,ES引入了分片技术。一个分片本身就是一个完成的搜索引擎,文档存储在分片中,而分片会被分配到集群中的各个节点中,随着集群的扩大和缩小,ES会自动的将分片在节点之间进行迁移,以保证集群能保持一种平衡。分片有以下特点:ES的一个索引可以包含多个分片(shard);
每一个分片(shard)都是一个最小的工作单元,承载部分数据; 每个shard都是一个lucene实例,有完整的简历索引和处理请求的能力; 增减节点时,shard会自动在nodes中负载均衡; 一个文档只能完整的存放在一个shard上 一个索引中含有shard的数量,默认值为5,在索引创建后这个值是不能被更改的。 优点:水平分割和扩展我们存放的内容索引;分发和并行跨碎片操作提高性能/吞吐量; 每一个shard关联的副本分片(replica shard)的数量,默认值为1,这个设置在任何时候都可以修改。 2、副本:replica 副本(replica shard)就是shard的冗余备份,它的主要作用:冗余备份,防止数据丢失;
shard异常时负责容错和负载均衡; ES的特性: 速度快、易扩展、弹性、灵活、操作简单、多语言客户端、X-Pack、hadoop/spark强强联手、开箱即用。分布式:横向扩展非常灵活
全文检索:基于lucene的强大的全文检索能力; 近实时搜索和分析:数据进入ES,可达到近实时搜索,还可进行聚合分析 高可用:容错机制,自动发现新的或失败的节点,重组和重新平衡数据 模式自由:ES的动态mapping机制可以自动检测数据的结构和类型,创建索引并使数据可搜索。 RESTful API:JSON + HTTP
es 几个重要的底层原理相关概念
1、Elasticsearch对复杂分布式机制的透明隐藏特性
- 分片机制
- shard副本
- 集群发现机制
- shard负载均衡
2、Elasticsearch的垂直扩容与水平扩容
- 垂直扩容:采购更强大的服务器,成本非常高昂,而且会有瓶颈,假设世界上最强大的服务器容量就是10T,但是当你的总数据量达到5000T的时候,你要采购多少台最强大的服务器啊
- 水平扩容:业界经常采用的方案,采购越来越多的普通服务器,性能比较一般,但是很多普通服务器组织在一起,就能构成强大的计算和存储能力
3.节点平等的分布式架构
- 节点对等,每个节点都能接收所有的请求
- 自动请求路由
- 响应收集
4、master节点
- 创建或删除索引
- 增加或删除节点
5.基于_version进行乐观锁并发控制
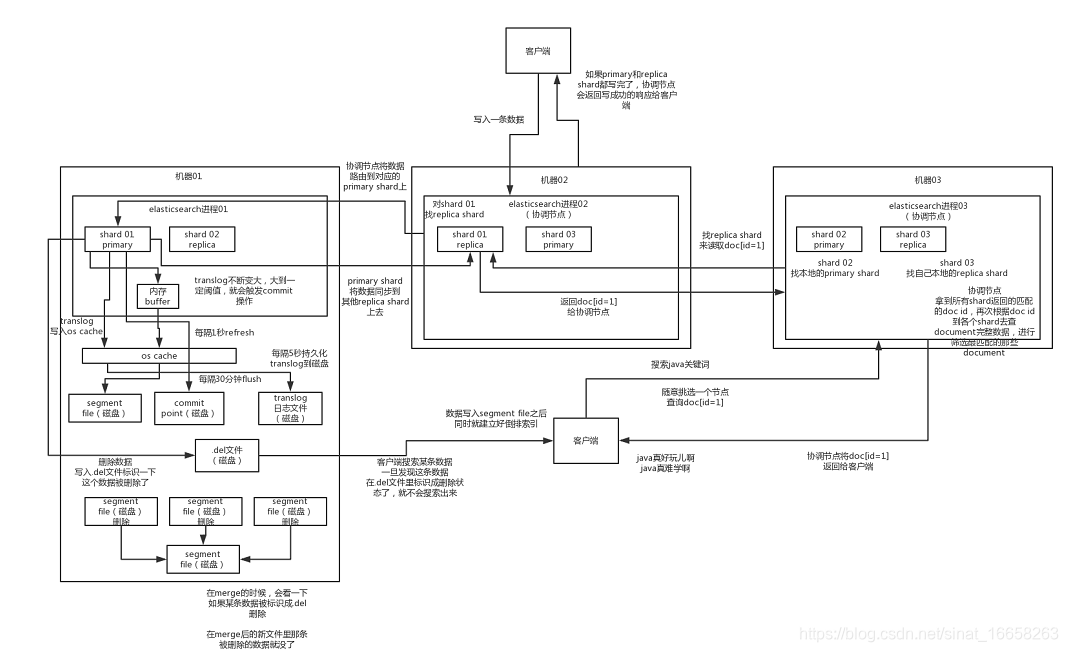
\es写入数据的过程
- 客户端选择一个node发送请求过去,这个node就是coordinating node (协调节点)
- coordinating node,对document进行路由,将请求转发给对应的node
- 实际上的node上的primary shard处理请求,然后将数据同步到replica node
- coordinating node,如果发现primary node和所有的replica node都搞定之后,就会返回请求到客户端
这个路由简单的说就是取模算法,比如说现在有3太服务器,这个时候传过来的id是5,那么5%3=2,就放在第2太服务器
写入数据底层原理:
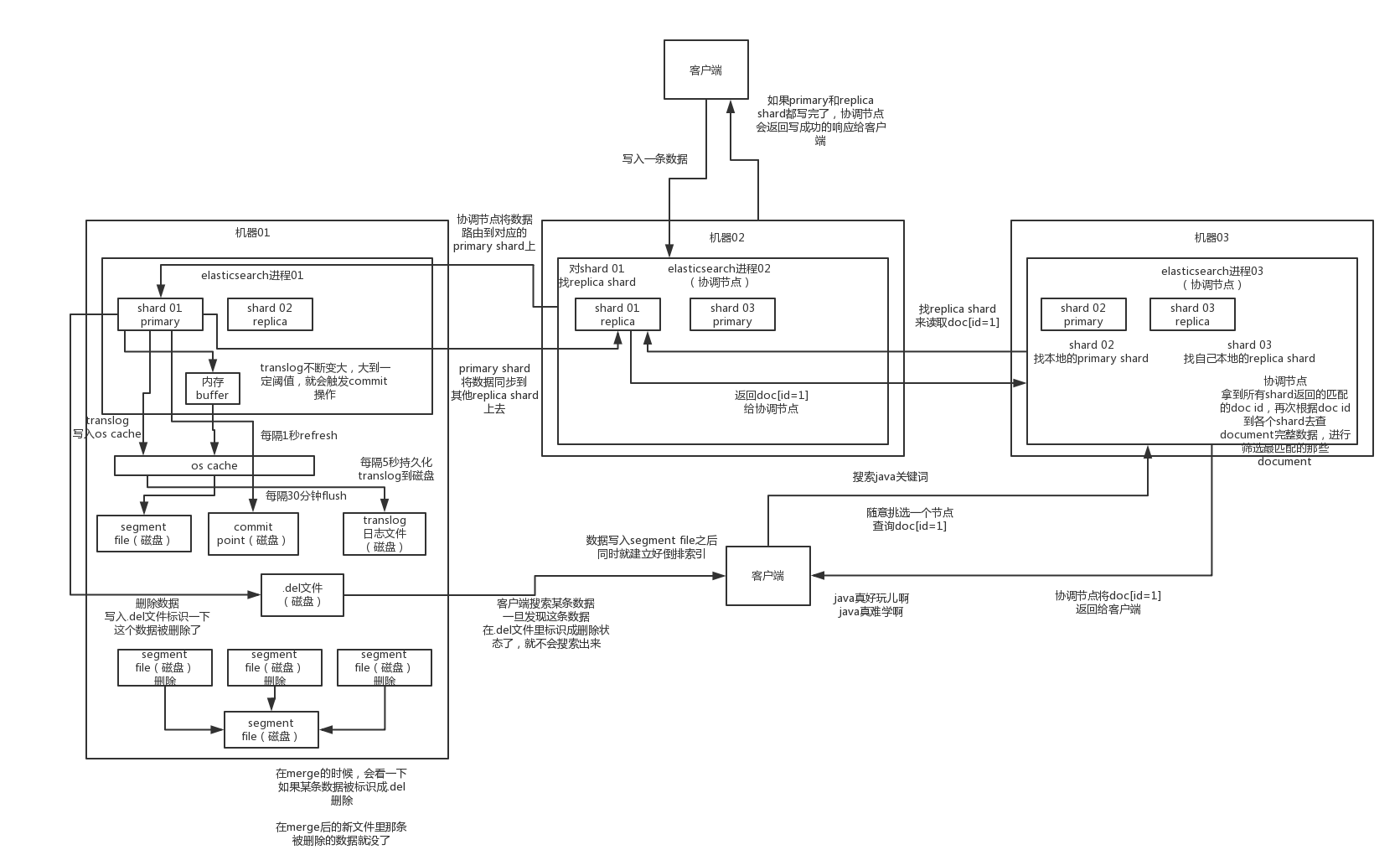
- 数据先写入到buffer里面,在buffer里面的数据时搜索不到的,同时将数据写入到translog日志文件之中
- 如果buffer快满了,或是一段时间之后(定时),就会将buffer数据refresh到一个新的OS cache之中,然后每隔1秒,就会将OS cache的数据写入到segment file之中,但是如果每一秒钟没有新的数据到buffer之中,就会创建一个新的空的segment file,只要buffer中的数据被refresh到OS cache之中,就代表这个数据可以被搜索到了。当然可以通过restful api 和Java api,手动的执行一次refresh操作,就是手动的将buffer中的数据刷入到OS cache之中,让数据立马搜索到,只要数据被输入到OS cache之中,buffer的内容就会被清空了。同时进行的是,数据到shard之后,就会将数据写入到translog之中,每隔5秒将translog之中的数据持久化到磁盘之中
- 重复以上的操作,每次一条数据写入buffer,同时会写入一条日志到translog日志文件之中去,这个translog文件会不断的变大,当达到一定的程度之后,就会触发commit操作。
- 将一个commit point写入到磁盘文件,里面标识着这个commit point 对应的所有segment file
- 强行将OS cache 之中的数据都fsync到磁盘文件中去。
- 解释:translog的作用:在执行commit之前,所有的而数据都是停留在buffer或OS cache之中,无论buffer或OS cache都是内存,一旦这台机器死了,内存的数据就会丢失,所以需要将数据对应的操作写入一个专门的日志问价之中,一旦机器出现宕机,再次重启的时候,es会主动的读取translog之中的日志文件的数据,恢复到内存buffer和OS cache之中。
- 将现有的translog文件进行清空,然后在重新启动一个translog,此时commit就算是成功了,默认的是每隔30分钟进行一次commit,但是如果translog的文件过大,也会触发commit,整个commit过程就叫做一个flush操作,我们也可以通过ES API,手动执行flush操作,手动将OS cache 的数据fsync到磁盘上面去,记录一个commit point,清空translog文件
- 补充:其实translog的数据也是先写入到OS cache之中的,默认每隔5秒之中将数据刷新到硬盘中去,也就是说,可能有5秒的数据仅仅停留在buffer或者translog文件的OS cache中,如果此时机器挂了,会丢失5秒的数据,但是这样的性能比较好,我们也可以将每次的操作都必须是直接fsync到磁盘,但是性能会比较差。
- 如果时删除操作,commit的时候会产生一个.del文件,里面讲某个doc标记为delete状态,那么搜索的时候,会根据.del文件的状态,就知道那个文件被删除了。
- 如果时更新操作,就是讲原来的doc标识为delete状态,然后重新写入一条数据即可。
- buffer每次更新一次,就会产生一个segment file 文件,所以在默认情况之下,就会产生很多的segment file 文件,将会定期执行merge操作
- 每次merge的时候,就会将多个segment file 文件进行合并为一个,同时将标记为delete的文件进行删除,然后将新的segment file 文件写入到磁盘,这里会写一个commit point,标识所有的新的segment file,然后打开新的segment file供搜索使用。
es读数据过程
查询,GET某一条的数据,写入某个document,这个document会自动给你分配一个全局的唯一ID,同时跟住这个ID进行hash路由到对应的primary shard上面去,当然也可以手动的设置ID
- 客户端发送任何一个请求到任意一个node,成为coordinate node
- coordinate node 对document进行路由,将请求转发到对应的node,此时会使用round-robin随机轮训算法,在primary shard 以及所有的replica中随机选择一个,让读请求负载均衡,
- 接受请求的node,返回document给coordinate note
- coordinate node返回给客户端
es搜索数据过程
- 客户端发送一个请求给coordinate node
- 协调节点将搜索的请求转发给所有的shard对应的primary shard 或replica shard
- query phase:每一个shard 将自己搜索的结果(其实也就是一些唯一标识),返回给协调节点,有协调节点进行数据的合并,排序,分页等操作,产出最后的结果
- fetch phase ,接着由协调节点,根据唯一标识去各个节点进行拉去数据,最总返回给客户端
写入数据的底层介绍
- 数据先写入到buffer里面,在buffer里面的数据时搜索不到的,同时将数据写入到translog日志文件之中
- 如果buffer快满了,或是一段时间之后,就会将buffer数据refresh到一个新的OS cache之中,然后每隔1秒,就会将OS cache的数据写入到segment file之中,但是如果每一秒钟没有新的数据到buffer之中,就会创建一个新的空的segment file,只要buffer中的数据被refresh到OS cache之中,就代表这个数据可以被搜索到了。当然可以通过restful api 和Java api,手动的执行一次refresh操作,就是手动的将buffer中的数据刷入到OS cache之中,让数据立马搜索到,只要数据被输入到OS cache之中,buffer的内容就会被清空了。同时进行的是,数据到shard之后,就会将数据写入到translog之中,每隔5秒将translog之中的数据持久化到磁盘之中
- 重复以上的操作,每次一条数据写入buffer,同时会写入一条日志到translog日志文件之中去,这个translog文件会不断的变大,当达到一定的程度之后,就会触发commit操作。
- 将一个commit point写入到磁盘文件,里面标识着这个commit point 对应的所有segment file
- 强行将OS cache 之中的数据都fsync到磁盘文件中去。 解释:translog的作用:在执行commit之前,所有的而数据都是停留在buffer或OS cache之中,无论buffer或OS cache都是内存,一旦这台机器死了,内存的数据就会丢失,所以需要将数据对应的操作写入一个专门的日志问价之中,一旦机器出现宕机,再次重启的时候,es会主动的读取translog之中的日志文件的数据,恢复到内存buffer和OS cache之中。
- 将现有的translog文件进行清空,然后在重新启动一个translog,此时commit就算是成功了,默认的是每隔30分钟进行一次commit,但是如果translog的文件过大,也会触发commit,整个commit过程就叫做一个flush操作,我们也可以通过ES API,手动执行flush操作,手动将OS cache 的数据fsync到磁盘上面去,记录一个commit point,清空translog文件 补充:其实translog的数据也是先写入到OS cache之中的,默认每隔5秒之中将数据刷新到硬盘中去,也就是说,可能有5秒的数据仅仅停留在buffer或者translog文件的OS cache中,如果此时机器挂了,会丢失5秒的数据,但是这样的性能比较好,我们也可以将每次的操作都必须是直接fsync到磁盘,但是性能会比较差。
- 如果时删除操作,commit的时候会产生一个.del文件,里面讲某个doc标记为delete状态,那么搜索的时候,会根据.del文件的状态,就知道那个文件被删除了。
- 如果时更新操作,就是讲原来的doc标识为delete状态,然后重新写入一条数据即可。
- buffer每次更新一次,就会产生一个segment file 文件,所以在默认情况之下,就会产生很多的segment file 文件,将会定期执行merge操作
- 每次merge的时候,就会将多个segment file 文件进行合并为一个,同时将标记为delete的文件进行删除,然后将新的segment file 文件写入到磁盘,这里会写一个commit point,标识所有的新的segment file,然后打开新的segment file供搜索使用。
总之,segment的四个核心概念,refresh,flush,translog、merge
搜索的底层原理
查询过程大体上分为查询和取回这两个阶段,广播查询请求到所有相关分片,并将它们的响应整合成全局排序后的结果集合,这个结果集合会返回给客户端。
-
查询阶段
- 当一个节点接收到一个搜索请求,这这个节点就会变成协调节点,第一步就是将广播请求到搜索的每一个节点的分片拷贝,查询请求可以被某一个主分片或某一个副分片处理,协调节点将在之后的请求中轮训所有的分片拷贝来分摊负载。
- 每一个分片将会在本地构建一个优先级队列,如果客户端要求返回结果排序中从from 名开始的数量为size的结果集,每一个节点都会产生一个from+size大小的结果集,因此优先级队列的大小也就是from+size,分片仅仅是返回一个轻量级的结果给协调节点,包括结果级中的每一个文档的ID和进行排序所需要的信息。
- 协调节点将会将所有的结果进行汇总,并进行全局排序,最总得到排序结果。
-
取值阶段
- 查询过程得到的排序结果,标记处哪些文档是符合要求的,此时仍然需要获取这些文档返回给客户端
- 协调节点会确定实际需要的返回的文档,并向含有该文档的分片发送get请求,分片获取的文档返回给协调节点,协调节点将结果返回给客户端。
倒排索引
倒排索引就建立分词与文档之间的映射关系,在倒排索引之中,数据时面向分词的而不是面向文档的。
在海量数据中怎样提高效率
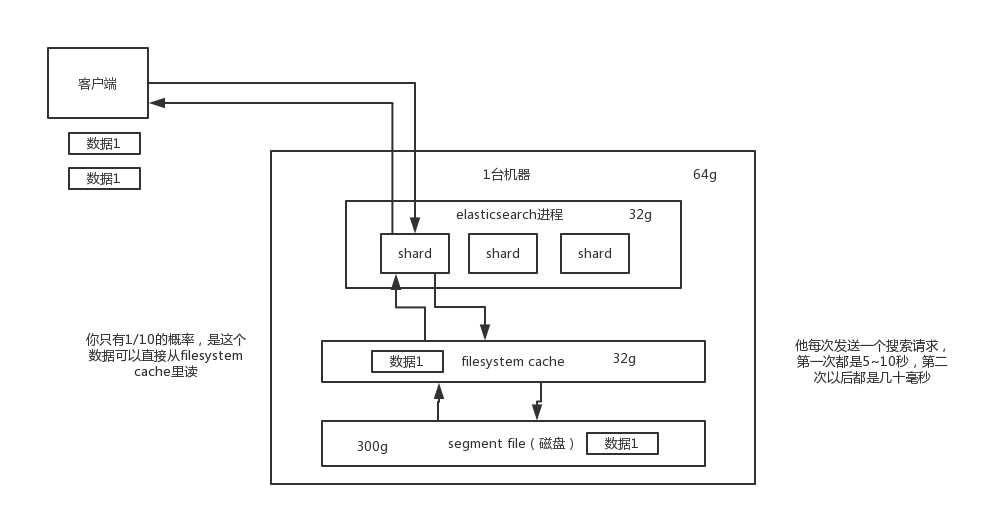
- filesystem cache ES的搜索引擎是严重的依赖底层的filesystem cache,如果给filesystem cache更多的内存,尽量让内存可以容纳所有的index segment file 索引数据文件
- 数据预热 对于那些你觉得比较热的数据,经常会有人访问的数据,最好做一个专门的缓存预热子系统,就是对热数据,每隔一段时间,你就提前访问以下,让数据进入filesystem cache里面去,这样期待下次访问的时候,性能会更好一些。
- 冷热分离
关于ES的性能优化,数据拆分,将大量的搜索不到的字段,拆分到别的存储中去,这个类似于MySQL的分库分表的垂直才分。
- document的模型设计
不要在搜索的时候去执行各种复杂的操作,尽量在document模型设计的时候,写入的时候就完成了,另外对于一些复杂的操作,尽量要避免
- 分页性能优化
翻页的时候,翻得越深,每个shard返回的数据越多,而且协调节点处理的时间越长,当然是用scroll,scroll会一次性的生成所有数据的一个快照,然后每次翻页都是通过移动游标完成的。 api 只是在一页一页的往后翻